Всего найдено: 24
Здравствуйте! Прочитала у вас, что _cash_ кириллицей правильно писать через «е»: (кеш). Относится ли данное правило к написанию фамилии _Cash_? _Кеш_ или _Кэш_? Спасибо.
Ответ справочной службы русского языка
Нет, фамилии пишутся по сложившейся традиции, написание закрепляется в документах.
Добрый день! Как правильно писать — кэш или кеш, когда речь идет о наличных деньгах?
Ответ справочной службы русского языка
Это слово уже зафиксировано в академическом орфографическом словаре.
«Кэшбек будет начислен в течение 14 рабочих дней.» — в данном предложении, в слове «течение», в окончании, не должна ли стоять «и»?
Ответ справочной службы русского языка
Предлог в течение написан верно. Обратите внимание: предпочтительно писать кешбэк.
Здравствуйте, как правильно пишется: кешбэк, кэшбэк или кешбэк? В вопросе № 277210 «Грамота» какое-то время назад давала ответ, что правильно кешбэк, но может быть уже что-то изменилось. Слово очень часто используется и, возможно, язык его уже освоил. Спасибо.
Ответ справочной службы русского языка
Кешбэк — употребительный и корректный вариант написания.
Добрый день! Скажите, пожалуйста, правильно ли проставлены запятые в предложении: «На данный момент, сумма кэшбэка может отображаться неверно, но, в процессе обработки заказа, кэшбэк поступит правильно на Ваш баланс.» И в роли какой части речи выступает «в процессе обработки заказа»?
Ответ справочной службы русского языка
В этом предложении нужна только одна запятая перед но. Обратите внимание, что вторая часть предложения составлена небезупречно, и ее лучше перестроить: На данный момент сумма кешбэка может отображаться неверно, но в процессе обработки заказа на Ваш баланс поступит правильная сумма.
Если Вы имеете в виду синтаксическую роль, которую выполняет словосочетание в предложении, то это обстоятельство времени.
Поясните, пожалуйста, как правильно пишется «кЕш» или «кЭш» (в смысловом значении «промежуточный буфер памяти»)? В различных словарях разная информация по поводу написания, например: Орфографический словарь: кеш, -а, тв. -ем (фин., инф.) Большой толковый словарь: КЭШ, -а; м. [англ. cache] Информ. Память ЭВМ, предназначенная для хранения промежуточных результатов, а также часто используемых данных и команд.
Ответ справочной службы русского языка
В вопросах правописания рекомендуем ориентироваться на орфографический словарь, то есть использовать вариант кеш.
Нужна ли запятая перед «как» в таком предложении: <<писать через «е» такие слова как «кэш«, «хэш» и «каратэ» — это сущее издевательство над логикой>> ? А перед тире? (пример с вашего сайта)
Ответ справочной службы русского языка
Запятые нужны: …писать через «е» такие слова, как «кэш«, «хэш» и «каратэ», – это сущее издевательство над логикой. Это предложение из вопроса нашего посетителя. В текстах вопросов сохраняется орфография и пунктуация автора.
Добрый день.
В разделе «Справка» вы пишете, что верное написание по-русски — «хештег».
Однако слово ещё не зафиксировано в словарях, а частотность употребления формы «хэштег» – с буквой «э» – значительно выше.
Как быть?
Ответ справочной службы русского языка
В «Русском орфографическом словаре» (4-е изд., М., 2012) уже зафиксированы слова с первой частью хеш… (передающей англ. hash): хеш, хеширование, хеш-код. Кроме того, пишется кеш (не кэш), флеш (не флэш). По аналогии: хештег.
Добрый день! Очень срочный вопрос: финансовая услуга по возврату части средств за оплаченный товар называется «кешбэк». Здравая логика подсказывает, что слово должно писаться именно так, но целиком на сайте нигде не встречается. Подскажите, может, верно «кешбек» или «кэшбэк»? И зафиксировано ли это слово где-нибудь целиком?
Ответ справочной службы русского языка
Это слово должно писаться так: кешбэк (ср.: флешбэк).
В США иногда встречается использование инициалов вместо имени. Например, JW вместо Джон Уолтер. В некоторых случаях инициалы в принципе не расшифровываются. Например, певец Джонни Кэш получил при рождение имя JR. Подскажите, пожалуйста, как правильно передавать на русский язык, например, инициалы JW: Джей-Даблю, Джей Дабл-ю, Джейдабл-ю? В источниках можно встретить все три варианта написания.
Ответ справочной службы русского языка
Корректно: Джей Дабл-ю.
Здравствуйте.
Перехожу к сути вопроса в уже порядком затянувшееся продолжение к теме о «кеш/кэш«. ))
Нельзя ли все же как-то обозначать допустимость написания буквы «э» в данном случае, ссылаясь на авторитетные специализированные источники? Вариативность написания «э/е» в данном случае помогла бы избежать в некотором роде «пуризма» в этом вопросе. Часто прибегаю к помощи вашего сайта (спасибо за удобную навигацию и информативность), и хотелось бы видеть, что написание этого слова может быть вариативным, тем более что так оно и есть. Также буду признательна за ссылку, где можно обратиться к составителям «Русского орфографического словаря», если таковая существует и вас это не затруднит.
Ответ справочной службы русского языка
Нужные словарные рекомендации есть в «Проверке слова».
С предложениями для орфографистов можно обратиться в Институт русского языка РАН:
Федеральное государственное бюджетное учреждение науки Институт русского языка им. В. В. Виноградова РАН
119019, Москва, ул. Волхонка, д. 18/2.
Телефон: (+7 495) 695-26-60
Факс: (+7 495) 695-26-03
И снова здравствуйте. Вновь я со своим «кэш/кеш».
На сайте Института русского языка им. В. В. Виноградова РАН опубликованы Ответы [авторов книги «Правила русской орфографии и пунктуации: Полный академический справочник» (М., 2006)] на замечания кафедры русского языка филологического факультета МГУ. Здесь наглядная иллюстрация «метаний академиков» в плане внесения изменений и дополнений в существующие правила РЯ.
http://www.ruslang.ru/doc/to_msu.pdf
Впрочем, в список не вошли многие вопросы, адресованные авторам, неведомо по каким причинам.
Смотрим страницу 10, где как раз приоткрывается немного завеса тайны над лингвистическим вопросом. Цитирую: «Орфографическое правило может основываться на произношении там, где последнее устойчиво».
Смотрим полный академ. справочник под ред. Лопатина:§ 8. Не в начале корня после согласных буква э пишется для передачи гласного э и одновременно для указания на твердость предшествующего согласного в следующих случаях.
1. В немногих нарицательных словах иноязычного происхождения. Перечень основных слов: мэр, мэтр ‘учитель, мастер’, пленэр, пэр, рэкет, рэп, сэр; то же в производных от них словах, напр.: мэрия, пэрство, рэкетир. Круг других слов (преимущественно узкоспециальных) определяется орфографическим словарем.
Пэр-сэр-мэр здесь не при чем. И ориентироваться стоит, на мой взгляд, на специализированные словари, список которых я предоставляла в предыдущем письме. Заранее спасибо, с надеждой на ответ,
Ответ справочной службы русского языка
Здесь как раз все последовательно, никаких метаний. Авторы консервативно предлагают не увеличивать имеющееся количество корней с Э, справедливо предполагая, что новые для русского языка слова имеют тенденцию к освоению и смягчению, нельзя чисто орфографическим путем лишать их шанса фонетически освоиться в будущем. Учитывается при этом, что в русском языке множество заимствованных слов уже пишутся с Е после твердого согласного, и таких слов куда больше, чем слов с Э. Иначе и слово «бутерброд», и «компьютер» нужно писать с ТЭ… Напомним также и о некогда бытовавшем (полустихийном) написании «плэйер».
В продолжение вопроса о «кэш/кеш»:
Все, что мы увидели, однозначно говорит в пользу того, что «Кэш» — является узусом. Узус может фиксироваться словарями (толковыми, фразеологическими, орфографическими и т. п.) и далее кодифицироваться в языковую норму, что сейчас и происходит.
Ответ справочной службы русского языка
Еще раз спасибо за дельные рассуждения. Но вопроса так и нет…
Здравствуйте! В своих ответах к вопросу о правильном написании «кэш/кеш» вы придерживаетесь написания через «е».
«Самый новейший толковый словарь русского языка XXI века» авторства Шагаловой издан в 2011 году. Опирается он на правила, утвержденные в 1956 году. Можно сказать, что словарь не может быть слишком или не слишком старым, это действующий в настоящее время словарь. Но как быть с тем, что в данном случае существуют более свежие авторитетные источники, и в немалом количестве, поддерживающие написание «кэш»?Итак, сухие факты:
— Между тем, проверка слова на Грамоте.ру дает недвусмысленный ответ — http://www.gramota.ru/slovari/dic/?word=%EA%FD%F8&all=x&lop=x&bts=x&zar=x&ag=x&ab=x&sin=x&lv=x&az=x&pe=x
(результат поиска из большого толкового словаря Кузнецова)
— «Толковый словарь по вычислительной технике» Microsoft Press 1995 — дает только кэш, кэш-диска, кэш-память
— Информатика и компьютерные технологии: Основные термины: Толковый словарь: Более 1000 базовых понятий и терминов, автор: Фридланд А.Я. 2002 г. дает только кэш-память.
— Современный англо русский словарь компьютерных технологий, под редакцией доктора физико-математических наук Николая Алексеевича Голованова — только Кэш на любой лад и в любых словосочетаниях.
— Англо-русский и русско-английский словарь ПК, автор: И. Мизинина,А. Мизинина, И. Жильцов — снова Кэш на любой лад и ни одного Кеш. (прикреплено в архиве, можно убедиться самостоятельно)
— Новый словарь иностранных слов — на данный момент в доступных нам словарях зафиксировано только слово кэш в таком написании (см. Захаренко Е. Н., Комарова Л. Н., Нечаева И. В.)
— Англо-Русский Словарь Сокращений в Области Информационных Технологий, составитель Ю.Цуканов — цитата:BTAC — branch target address cache, кэш-память адресов ветвлений; ECS — external cache socket, гнездо для подключения внешней кэш-памяти; ICDA — Integrated Cashed Disk Array, дисковая матрица со встроенной кэш-памятью
Следующая подборка:
Открываем словарь Lingvo. Среди десятков терминов с участием cache в переводе нет ни одного варианта через букву «е» («кеш»).
Открываем PolyGlossum. Среди его словарей та же картина.
Context. Та же картина.
Открываем Большую энциклопедию Кирилла и Мефодия 2000: КЭШ-ПАМЯТЬ.
Открываем Norton Help — Glossary. кэш, кэширование.
Смотрим Windows XP Help — Glossary. И — кэш!Лично я за неимением иного пользуюсь Interpretatio, и вот результат оттуда:
— КешФ. А. Брокгауз, И. А. Ефрон. Энциклопедический словарь
Кеш (Kesch) — высочайшая вершина (3422 м) в северо-ретийских Альпах, в швейцарском кантоне Граубюнден, на водоразделе между Рейном и Дунаем, на север от Альбульского прохода. С юго-запада и востока обрывиста, на севере отложе, с фирновым полем. С вершины один из обширнейших видов на Энгадинские АльпыВ. В. Лопатин. Орфографический словарь
кеш кеш, -а, тв. -ем— Кэш
Словарь компьютерных терминов
Кэш Cache. При просмотре в интернет страниц ваш браузер создает у вас на компьютере копии этих страниц — кэширует их. При попытке повторного просмотра страниц, которые вы уже посетили, браузер уже не будет запрашивать их с веб-сервера в интернет, где эти страницы расположены, а извлечет из кэша.Ну и наконец, в статье на тему «э и е в заимствованиях» авторства И.В. Нечаевой, кандидата филологических наук, научного сотрудника отдела культуры русской речи ИРЯ РАН, отдельно отмечается, что «э» особенно широко применяется в словах с односложной основой (таких как «кэш»), например, гэг, кэт, мэн, тэн, хэнд, шэн. http://www.gramma.ru/RUS/?id=1.57
Ответ справочной службы русского языка
Спасибо за обилие ссылок. Но вопрос-то в чем? Мы не можем изменить словарную рекомендацию. Единственный возможный шаг — передать эти ссылки редакторам и составителям «Русского орфографического словаря».
Здравствуйте. Орфографический словарь дает написание «кеш», а толковый «кэш» (оба в информационном значении). Как правильно и каким словарем руководствоваться при разногласии в них? Спасибо.
Ответ справочной службы русского языка
Правильно: кеш. Колебания в написании недавно заимствованных слов и неодинаковая их фиксация в разных словарях (или разных изданиях одного и того же словаря) – вещь вполне естественная: слово осваивается в языке. В спорных случаях лучше придерживаться рекомендаций орфографического словаря.

Diagram of a CPU memory cache operation
In computing, a cache ( KASH)[1] is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests that can be served from the cache, the faster the system performs.[2]
To be cost-effective and to enable efficient use of data, caches must be relatively small. Nevertheless, caches have proven themselves in many areas of computing, because typical computer applications access data with a high degree of locality of reference. Such access patterns exhibit temporal locality, where data is requested that has been recently requested already, and spatial locality, where data is requested that is stored physically close to data that has already been requested.
Motivation[edit]
There is an inherent trade-off between size and speed (given that a larger resource implies greater physical distances) but also a tradeoff between expensive, premium technologies (such as SRAM) vs cheaper, easily mass-produced commodities (such as DRAM or hard disks).
The buffering provided by a cache benefits one or both of latency and throughput (bandwidth):
Latency[edit]
A larger resource incurs a significant latency for access – e.g. it can take hundreds of clock cycles for a modern 4 GHz processor to reach DRAM. This is mitigated by reading in large chunks, in the hope that subsequent reads will be from nearby locations. Prediction or explicit prefetching might also guess where future reads will come from and make requests ahead of time; if done correctly the latency is bypassed altogether.
Throughput[edit]
The use of a cache also allows for higher throughput from the underlying resource, by assembling multiple fine grain transfers into larger, more efficient requests. In the case of DRAM circuits, this might be served by having a wider data bus. For example, consider a program accessing bytes in a 32-bit address space, but being served by a 128-bit off-chip data bus; individual uncached byte accesses would allow only 1/16th of the total bandwidth to be used, and 80% of the data movement would be memory addresses instead of data itself. Reading larger chunks reduces the fraction of bandwidth required for transmitting address information.
Operation[edit]
Hardware implements cache as a block of memory for temporary storage of data likely to be used again. Central processing units (CPUs), solid-state drives (SSDs) and hard disk drives (HDDs) frequently include hardware-based cache, while web browsers and web servers commonly rely on software caching.
A cache is made up of a pool of entries. Each entry has associated data, which is a copy of the same data in some backing store. Each entry also has a tag, which specifies the identity of the data in the backing store of which the entry is a copy. Tagging allows simultaneous cache-oriented algorithms to function in multilayered fashion without differential relay interference.
When the cache client (a CPU, web browser, operating system) needs to access data presumed to exist in the backing store, it first checks the cache. If an entry can be found with a tag matching that of the desired data, the data in the entry is used instead. This situation is known as a cache hit. For example, a web browser program might check its local cache on disk to see if it has a local copy of the contents of a web page at a particular URL. In this example, the URL is the tag, and the content of the web page is the data. The percentage of accesses that result in cache hits is known as the hit rate or hit ratio of the cache.
The alternative situation, when the cache is checked and found not to contain any entry with the desired tag, is known as a cache miss. This requires a more expensive access of data from the backing store. Once the requested data is retrieved, it is typically copied into the cache, ready for the next access.
During a cache miss, some other previously existing cache entry is removed in order to make room for the newly retrieved data. The heuristic used to select the entry to replace is known as the replacement policy. One popular replacement policy, «least recently used» (LRU), replaces the oldest entry, the entry that was accessed less recently than any other entry (see cache algorithm). More efficient caching algorithms compute the use-hit frequency against the size of the stored contents, as well as the latencies and throughputs for both the cache and the backing store. This works well for larger amounts of data, longer latencies, and slower throughputs, such as that experienced with hard drives and networks, but is not efficient for use within a CPU cache.[citation needed]
Writing policies[edit]

A write-through cache with no-write allocation
A write-back cache with write allocation
When a system writes data to cache, it must at some point write that data to the backing store as well. The timing of this write is controlled by what is known as the write policy. There are two basic writing approaches:[3]
- Write-through: write is done synchronously both to the cache and to the backing store.
- Write-back: initially, writing is done only to the cache. The write to the backing store is postponed until the modified content is about to be replaced by another cache block.
A write-back cache is more complex to implement, since it needs to track which of its locations have been written over, and mark them as dirty for later writing to the backing store. The data in these locations are written back to the backing store only when they are evicted from the cache, an effect referred to as a lazy write. For this reason, a read miss in a write-back cache (which requires a block to be replaced by another) will often require two memory accesses to service: one to write the replaced data from the cache back to the store, and then one to retrieve the needed data.
Other policies may also trigger data write-back. The client may make many changes to data in the cache, and then explicitly notify the cache to write back the data.
Since no data is returned to the requester on write operations, a decision needs to be made on write misses, whether or not data would be loaded into the cache.
This is defined by these two approaches:
- Write allocate (also called fetch on write): data at the missed-write location is loaded to cache, followed by a write-hit operation. In this approach, write misses are similar to read misses.
- No-write allocate (also called write-no-allocate or write around): data at the missed-write location is not loaded to cache, and is written directly to the backing store. In this approach, data is loaded into the cache on read misses only.
Both write-through and write-back policies can use either of these write-miss policies, but usually they are paired in this way:[4]
- A write-back cache uses write allocate, hoping for subsequent writes (or even reads) to the same location, which is now cached.
- A write-through cache uses no-write allocate. Here, subsequent writes have no advantage, since they still need to be written directly to the backing store.
Entities other than the cache may change the data in the backing store, in which case the copy in the cache may become out-of-date or stale. Alternatively, when the client updates the data in the cache, copies of those data in other caches will become stale. Communication protocols between the cache managers which keep the data consistent are known as coherency protocols.
Prefetch[edit]
On a cache read miss,
caches with a demand paging policy read the minimum amount from the backing store.
For example, demand-paging virtual memory reads one page of virtual memory (often 4 kBytes) from disk into the disk cache in RAM.
For example, a typical CPU reads a single L2 cache line of 128 bytes from DRAM into the L2 cache, and a single L1 cache line of 64 bytes from the L2 cache into the L1 cache.
Caches with a prefetch input queue
or more general anticipatory paging policy
go further—they not only read the chunk requested, but guess that the next chunk or two will soon be required, and so prefetch that data into the cache ahead of time.
Anticipatory paging is especially helpful
when the backing store has a long latency to read the first chunk and much shorter times to sequentially read the next few chunks, such as disk storage and DRAM.
A few operating systems go further with a loader that always pre-loads the entire executable into RAM.
A few caches go even further, not only pre-loading an entire file, but also starting to load other related files that may soon be requested, such as the page cache associated with a prefetcher or the web cache associated with link prefetching.
Examples of hardware caches[edit]
CPU cache[edit]
Small memories on or close to the CPU can operate faster than the much larger main memory.[5] Most CPUs since the 1980s have used one or more caches, sometimes in cascaded levels; modern high-end embedded, desktop and server microprocessors may have as many as six types of cache (between levels and functions).[6] Examples of caches with a specific function are the D-cache and I-cache and the translation lookaside buffer for the MMU.
GPU cache[edit]
Earlier graphics processing units (GPUs) often had limited read-only texture caches, and introduced Morton order swizzled textures to improve 2D cache coherency. Cache misses would drastically affect performance, e.g. if mipmapping was not used. Caching was important to leverage 32-bit (and wider) transfers for texture data that was often as little as 4 bits per pixel, indexed in complex patterns by arbitrary UV coordinates and perspective transformations in inverse texture mapping.
As GPUs advanced (especially with GPGPU compute shaders) they have developed progressively larger and increasingly general caches, including instruction caches for shaders, exhibiting increasingly common functionality with CPU caches. For example, GT200 architecture GPUs did not feature an L2 cache, while the Fermi GPU has 768 KB of last-level cache, the Kepler GPU has 1536 KB of last-level cache, and the Maxwell GPU has 2048 KB of last-level cache. These caches have grown to handle synchronisation primitives between threads and atomic operations, and interface with a CPU-style MMU.
DSPs[edit]
Digital signal processors have similarly generalised over the years. Earlier designs used scratchpad memory fed by DMA, but modern DSPs such as Qualcomm Hexagon often include a very similar set of caches to a CPU (e.g. Modified Harvard architecture with shared L2, split L1 I-cache and D-cache).[7]
Translation lookaside buffer[edit]
A memory management unit (MMU) that fetches page table entries from main memory has a specialized cache, used for recording the results of virtual address to physical address translations. This specialized cache is called a translation lookaside buffer (TLB).[8]
In-network cache[edit]
Information-centric networking[edit]
Information-centric networking (ICN) is an approach to evolve the Internet infrastructure away from a host-centric paradigm, based on perpetual connectivity and the end-to-end principle, to a network architecture in which the focal point is identified information (or content or data). Due to the inherent caching capability of the nodes in an ICN, it can be viewed as a loosely connected network of caches, which has unique requirements of caching policies. However, ubiquitous content caching introduces the challenge to content protection against unauthorized access, which requires extra care and solutions.[9]
Unlike proxy servers, in ICN the cache is a network-level solution. Therefore, it has rapidly changing cache states and higher request arrival rates; moreover, smaller cache sizes further impose a different kind of requirements on the content eviction policies. In particular, eviction policies for ICN should be fast and lightweight. Various cache replication and eviction schemes for different ICN architectures and applications have been proposed.
Policies[edit]
Time aware least recently used (TLRU)[edit]
The Time aware Least Recently Used (TLRU)[10] is a variant of LRU designed for the situation where the stored contents in cache have a valid life time. The algorithm is suitable in network cache applications, such as Information-centric networking (ICN), Content Delivery Networks (CDNs) and distributed networks in general. TLRU introduces a new term: TTU (Time to Use). TTU is a time stamp of a content/page which stipulates the usability time for the content based on the locality of the content and the content publisher announcement. Owing to this locality based time stamp, TTU provides more control to the local administrator to regulate in network storage.
In the TLRU algorithm, when a piece of content arrives, a cache node calculates the local TTU value based on the TTU value assigned by the content publisher. The local TTU value is calculated by using a locally defined function. Once the local TTU value is calculated the replacement of content is performed on a subset of the total content stored in cache node. The TLRU ensures that less popular and small life content should be replaced with the incoming content.
Least frequent recently used (LFRU)[edit]
The Least Frequent Recently Used (LFRU)[11] cache replacement scheme combines the benefits of LFU and LRU schemes. LFRU is suitable for ‘in network’ cache applications, such as Information-centric networking (ICN), Content Delivery Networks (CDNs) and distributed networks in general. In LFRU, the cache is divided into two partitions called privileged and unprivileged partitions. The privileged partition can be defined as a protected partition. If content is highly popular, it is pushed into the privileged partition. Replacement of the privileged partition is done as follows: LFRU evicts content from the unprivileged partition, pushes content from privileged partition to unprivileged partition, and finally inserts new content into the privileged partition. In the above procedure the LRU is used for the privileged partition and an approximated LFU (ALFU) scheme is used for the unprivileged partition, hence the abbreviation LFRU.
The basic idea is to filter out the locally popular contents with ALFU scheme and push the popular contents to one of the privileged partition.
Weather forecast[edit]
Back in 2010 The New York Times suggested «Type ‘weather’ followed by your zip code.»[12] By 2011, the use of smartphones with weather forecasting options was overly taxing AccuWeather servers; two requests within the same park would generate separate requests. An optimization by edge-servers to truncate the GPS coordinates to fewer decimal places meant that the cached results from the earlier query would be used. The number of to-the-server lookups per day dropped by half.[13]
Software caches[edit]
Disk cache[edit]
While CPU caches are generally managed entirely by hardware, a variety of software manages other caches. The page cache in main memory, which is an example of disk cache, is managed by the operating system kernel.
While the disk buffer, which is an integrated part of the hard disk drive or solid state drive, is sometimes misleadingly referred to as «disk cache», its main functions are write sequencing and read prefetching. Repeated cache hits are relatively rare, due to the small size of the buffer in comparison to the drive’s capacity. However, high-end disk controllers often have their own on-board cache of the hard disk drive’s data blocks.
Finally, a fast local hard disk drive can also cache information held on even slower data storage devices, such as remote servers (web cache) or local tape drives or optical jukeboxes; such a scheme is the main concept of hierarchical storage management. Also, fast flash-based solid-state drives (SSDs) can be used as caches for slower rotational-media hard disk drives, working together as hybrid drives or solid-state hybrid drives (SSHDs).
Web cache[edit]
Web browsers and web proxy servers employ web caches to store previous responses from web servers, such as web pages and images. Web caches reduce the amount of information that needs to be transmitted across the network, as information previously stored in the cache can often be re-used. This reduces bandwidth and processing requirements of the web server, and helps to improve responsiveness for users of the web.[14]
Web browsers employ a built-in web cache, but some Internet service providers (ISPs) or organizations also use a caching proxy server, which is a web cache that is shared among all users of that network.
Another form of cache is P2P caching, where the files most sought for by peer-to-peer applications are stored in an ISP cache to accelerate P2P transfers. Similarly, decentralised equivalents exist, which allow communities to perform the same task for P2P traffic, for example, Corelli.[15]
Memoization[edit]
A cache can store data that is computed on demand rather than retrieved from a backing store. Memoization is an optimization technique that stores the results of resource-consuming function calls within a lookup table, allowing subsequent calls to reuse the stored results and avoid repeated computation. It is related to the dynamic programming algorithm design methodology, which can also be thought of as a means of caching.
Content delivery network[edit]
A content delivery network (CDN) is a network of distributed servers that deliver pages and other Web content to a user, based on the geographic locations of the user, the origin of the web page and the content delivery server.
CDNs began in the late 1990s as a way to speed up the delivery of static content, such as HTML pages, images and videos. By replicating content on multiple servers around the world and delivering it to users based on their location, CDNs can significantly improve the speed and availability of a website or application. When a user requests a piece of content, the CDN will check to see if it has a copy of the content in its cache. If it does, the CDN will deliver the content to the user from the cache.[16]
Cloud storage gateway[edit]
A cloud storage gateway, also known as an edge filer, is a hybrid cloud storage device that connects a local network to one or more cloud storage service, typically an object storage service such as Amazon S3. It provides a cache for frequently accessed data, providing high speed local access to frequently accessed data in the cloud storage service. Cloud storage gateways also provide additional benefits such as accessing cloud object storage through traditional file serving protocols as well as continued access to cached data during connectivity outages.[17]
Other caches[edit]
The BIND DNS daemon caches a mapping of domain names to IP addresses, as does a resolver library.
Write-through operation is common when operating over unreliable networks (like an Ethernet LAN), because of the enormous complexity of the coherency protocol required between multiple write-back caches when communication is unreliable. For instance, web page caches and client-side network file system caches (like those in NFS or SMB) are typically read-only or write-through specifically to keep the network protocol simple and reliable.
Search engines also frequently make web pages they have indexed available from their cache. For example, Google provides a «Cached» link next to each search result. This can prove useful when web pages from a web server are temporarily or permanently inaccessible.
Database caching can substantially improve the throughput of database applications, for example in the processing of indexes, data dictionaries, and frequently used subsets of data.
A distributed cache[18] uses networked hosts to provide scalability, reliability and performance to the application.[19] The hosts can be co-located or spread over different geographical regions.
Buffer vs. cache[edit]
The semantics of a «buffer» and a «cache» are not totally different; even so, there are fundamental differences in intent between the process of caching and the process of buffering.
Fundamentally, caching realizes a performance increase for transfers of data that is being repeatedly transferred. While a caching system may realize a performance increase upon the initial (typically write) transfer of a data item, this performance increase is due to buffering occurring within the caching system.
With read caches, a data item must have been fetched from its residing location at least once in order for subsequent reads of the data item to realize a performance increase by virtue of being able to be fetched from the cache’s (faster) intermediate storage rather than the data’s residing location. With write caches, a performance increase of writing a data item may be realized upon the first write of the data item by virtue of the data item immediately being stored in the cache’s intermediate storage, deferring the transfer of the data item to its residing storage at a later stage or else occurring as a background process. Contrary to strict buffering, a caching process must adhere to a (potentially distributed) cache coherency protocol in order to maintain consistency between the cache’s intermediate storage and the location where the data resides. Buffering, on the other hand,
- reduces the number of transfers for otherwise novel data amongst communicating processes, which amortizes overhead involved for several small transfers over fewer, larger transfers,
- provides an intermediary for communicating processes which are incapable of direct transfers amongst each other, or
- ensures a minimum data size or representation required by at least one of the communicating processes involved in a transfer.
With typical caching implementations, a data item that is read or written for the first time is effectively being buffered; and in the case of a write, mostly realizing a performance increase for the application from where the write originated. Additionally, the portion of a caching protocol where individual writes are deferred to a batch of writes is a form of buffering. The portion of a caching protocol where individual reads are deferred to a batch of reads is also a form of buffering, although this form may negatively impact the performance of at least the initial reads (even though it may positively impact the performance of the sum of the individual reads). In practice, caching almost always involves some form of buffering, while strict buffering does not involve caching.
A buffer is a temporary memory location that is traditionally used because CPU instructions cannot directly address data stored in peripheral devices. Thus, addressable memory is used as an intermediate stage. Additionally, such a buffer may be feasible when a large block of data is assembled or disassembled (as required by a storage device), or when data may be delivered in a different order than that in which it is produced. Also, a whole buffer of data is usually transferred sequentially (for example to hard disk), so buffering itself sometimes increases transfer performance or reduces the variation or jitter of the transfer’s latency as opposed to caching where the intent is to reduce the latency. These benefits are present even if the buffered data are written to the buffer once and read from the buffer once.
A cache also increases transfer performance. A part of the increase similarly comes from the possibility that multiple small transfers will combine into one large block. But the main performance-gain occurs because there is a good chance that the same data will be read from cache multiple times, or that written data will soon be read. A cache’s sole purpose is to reduce accesses to the underlying slower storage. Cache is also usually an abstraction layer that is designed to be invisible from the perspective of neighboring layers.
See also[edit]
- Cache coloring
- Cache hierarchy
- Cache-oblivious algorithm
- Cache stampede
- Cache language model
- Cache manifest in HTML5
- Dirty bit
- Five-minute rule
- Materialized view
- Memory hierarchy
- Pipeline burst cache
- Temporary file
References[edit]
- ^
«Cache». Oxford Dictionaries. Oxford Dictionaries. Archived from the original on 18 August 2012. Retrieved 2 August 2016. - ^ Zhong, Liang; Zheng, Xueqian; Liu, Yong; Wang, Mengting; Cao, Yang (February 2020). «Cache hit ratio maximization in device-to-device communications overlaying cellular networks». China Communications. 17 (2): 232–238. doi:10.23919/jcc.2020.02.018. ISSN 1673-5447. S2CID 212649328.
- ^ Bottomley, James (1 January 2004). «Understanding Caching». Linux Journal. Retrieved 1 October 2019.
- ^
John L. Hennessy; David A. Patterson (2011). Computer Architecture: A Quantitative Approach. Elsevier. pp. B–12. ISBN 978-0-12-383872-8. - ^ Su, Chao; Zeng, Qingkai (10 June 2021). Nicopolitidis, Petros (ed.). «Survey of CPU Cache-Based Side-Channel Attacks: Systematic Analysis, Security Models, and Countermeasures». Security and Communication Networks. 2021: 1–15. doi:10.1155/2021/5559552. ISSN 1939-0122.
- ^ «Intel Broadwell Core i7 5775C ‘128MB L4 Cache’ Gaming Behemoth and Skylake Core i7 6700K Flagship Processors Finally Available In Retail». 25 September 2015.Mentions L4 cache. Combined with separate I-Cache and TLB, this brings the total ‘number of caches (levels+functions) to 6
- ^ «qualcom Hexagon DSP SDK overview».
- ^ Frank Uyeda (2009). «Lecture 7: Memory Management» (PDF). CSE 120: Principles of Operating Systems. UC San Diego. Retrieved 4 December 2013.
- ^ Bilal, Muhammad; et al. (2019). «Secure Distribution of Protected Content in Information-Centric Networking». IEEE Systems Journal. 14 (2): 1–12. arXiv:1907.11717. Bibcode:2020ISysJ..14.1921B. doi:10.1109/JSYST.2019.2931813. S2CID 198967720.
- ^ Bilal, Muhammad; et al. (2017). «Time Aware Least Recent Used (TLRU) Cache Management Policy in ICN». IEEE 16th International Conference on Advanced Communication Technology (ICACT): 528–532. arXiv:1801.00390. Bibcode:2018arXiv180100390B. doi:10.1109/ICACT.2014.6779016. ISBN 978-89-968650-3-2. S2CID 830503.
- ^ Bilal, Muhammad; et al. (2017). «A Cache Management Scheme for Efficient Content Eviction and Replication in Cache Networks». IEEE Access. 5: 1692–1701. arXiv:1702.04078. Bibcode:2017arXiv170204078B. doi:10.1109/ACCESS.2017.2669344. S2CID 14517299.
- ^ Simon Mackie (3 May 2010). «9 More Simple Google Search Tricks». New York Times.
- ^ Chris Murphy (30 May 2011). «5 Lines Of Code In The Cloud». InformationWeek. p. 28.
300 million to 500 million fewer requests a day handled by AccuWeather servers
- ^ Multiple (wiki). «Web application caching». Docforge. Archived from the original on 12 December 2019. Retrieved 24 July 2013.
- ^ Gareth Tyson; Andreas Mauthe; Sebastian Kaune; Mu Mu; Thomas Plagemann. Corelli: A Dynamic Replication Service for Supporting Latency-Dependent Content in Community Networks (PDF). MMCN’09. Archived from the original (PDF) on 18 June 2015.
- ^ «Globally Distributed Content Delivery, by J. Dilley, B. Maggs, J. Parikh, H. Prokop, R. Sitaraman and B. Weihl, IEEE Internet Computing, Volume 6, Issue 5, November 2002» (PDF). Archived (PDF) from the original on 9 August 2017. Retrieved 25 October 2019.
- ^ «Definition: cloud storage gateway». SearchStorage. July 2014.
- ^ Paul, S; Z Fei (1 February 2001). «Distributed caching with centralized control». Computer Communications. 24 (2): 256–268. CiteSeerX 10.1.1.38.1094. doi:10.1016/S0140-3664(00)00322-4.
- ^ Khan, Iqbal (July 2009). «Distributed Caching on the Path To Scalability». MSDN. 24 (7).
Further reading[edit]
- «What Every Programmer Should Know About Memory»
- «Caching in the Distributed Environment»
Diagram of a CPU memory cache operation
In computing, a cache ( KASH)[1] is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests that can be served from the cache, the faster the system performs.[2]
To be cost-effective and to enable efficient use of data, caches must be relatively small. Nevertheless, caches have proven themselves in many areas of computing, because typical computer applications access data with a high degree of locality of reference. Such access patterns exhibit temporal locality, where data is requested that has been recently requested already, and spatial locality, where data is requested that is stored physically close to data that has already been requested.
Motivation[edit]
There is an inherent trade-off between size and speed (given that a larger resource implies greater physical distances) but also a tradeoff between expensive, premium technologies (such as SRAM) vs cheaper, easily mass-produced commodities (such as DRAM or hard disks).
The buffering provided by a cache benefits one or both of latency and throughput (bandwidth):
Latency[edit]
A larger resource incurs a significant latency for access – e.g. it can take hundreds of clock cycles for a modern 4 GHz processor to reach DRAM. This is mitigated by reading in large chunks, in the hope that subsequent reads will be from nearby locations. Prediction or explicit prefetching might also guess where future reads will come from and make requests ahead of time; if done correctly the latency is bypassed altogether.
Throughput[edit]
The use of a cache also allows for higher throughput from the underlying resource, by assembling multiple fine grain transfers into larger, more efficient requests. In the case of DRAM circuits, this might be served by having a wider data bus. For example, consider a program accessing bytes in a 32-bit address space, but being served by a 128-bit off-chip data bus; individual uncached byte accesses would allow only 1/16th of the total bandwidth to be used, and 80% of the data movement would be memory addresses instead of data itself. Reading larger chunks reduces the fraction of bandwidth required for transmitting address information.
Operation[edit]
Hardware implements cache as a block of memory for temporary storage of data likely to be used again. Central processing units (CPUs), solid-state drives (SSDs) and hard disk drives (HDDs) frequently include hardware-based cache, while web browsers and web servers commonly rely on software caching.
A cache is made up of a pool of entries. Each entry has associated data, which is a copy of the same data in some backing store. Each entry also has a tag, which specifies the identity of the data in the backing store of which the entry is a copy. Tagging allows simultaneous cache-oriented algorithms to function in multilayered fashion without differential relay interference.
When the cache client (a CPU, web browser, operating system) needs to access data presumed to exist in the backing store, it first checks the cache. If an entry can be found with a tag matching that of the desired data, the data in the entry is used instead. This situation is known as a cache hit. For example, a web browser program might check its local cache on disk to see if it has a local copy of the contents of a web page at a particular URL. In this example, the URL is the tag, and the content of the web page is the data. The percentage of accesses that result in cache hits is known as the hit rate or hit ratio of the cache.
The alternative situation, when the cache is checked and found not to contain any entry with the desired tag, is known as a cache miss. This requires a more expensive access of data from the backing store. Once the requested data is retrieved, it is typically copied into the cache, ready for the next access.
During a cache miss, some other previously existing cache entry is removed in order to make room for the newly retrieved data. The heuristic used to select the entry to replace is known as the replacement policy. One popular replacement policy, «least recently used» (LRU), replaces the oldest entry, the entry that was accessed less recently than any other entry (see cache algorithm). More efficient caching algorithms compute the use-hit frequency against the size of the stored contents, as well as the latencies and throughputs for both the cache and the backing store. This works well for larger amounts of data, longer latencies, and slower throughputs, such as that experienced with hard drives and networks, but is not efficient for use within a CPU cache.[citation needed]
Writing policies[edit]
A write-through cache with no-write allocation
A write-back cache with write allocation
When a system writes data to cache, it must at some point write that data to the backing store as well. The timing of this write is controlled by what is known as the write policy. There are two basic writing approaches:[3]
- Write-through: write is done synchronously both to the cache and to the backing store.
- Write-back: initially, writing is done only to the cache. The write to the backing store is postponed until the modified content is about to be replaced by another cache block.
A write-back cache is more complex to implement, since it needs to track which of its locations have been written over, and mark them as dirty for later writing to the backing store. The data in these locations are written back to the backing store only when they are evicted from the cache, an effect referred to as a lazy write. For this reason, a read miss in a write-back cache (which requires a block to be replaced by another) will often require two memory accesses to service: one to write the replaced data from the cache back to the store, and then one to retrieve the needed data.
Other policies may also trigger data write-back. The client may make many changes to data in the cache, and then explicitly notify the cache to write back the data.
Since no data is returned to the requester on write operations, a decision needs to be made on write misses, whether or not data would be loaded into the cache.
This is defined by these two approaches:
- Write allocate (also called fetch on write): data at the missed-write location is loaded to cache, followed by a write-hit operation. In this approach, write misses are similar to read misses.
- No-write allocate (also called write-no-allocate or write around): data at the missed-write location is not loaded to cache, and is written directly to the backing store. In this approach, data is loaded into the cache on read misses only.
Both write-through and write-back policies can use either of these write-miss policies, but usually they are paired in this way:[4]
- A write-back cache uses write allocate, hoping for subsequent writes (or even reads) to the same location, which is now cached.
- A write-through cache uses no-write allocate. Here, subsequent writes have no advantage, since they still need to be written directly to the backing store.
Entities other than the cache may change the data in the backing store, in which case the copy in the cache may become out-of-date or stale. Alternatively, when the client updates the data in the cache, copies of those data in other caches will become stale. Communication protocols between the cache managers which keep the data consistent are known as coherency protocols.
Prefetch[edit]
On a cache read miss,
caches with a demand paging policy read the minimum amount from the backing store.
For example, demand-paging virtual memory reads one page of virtual memory (often 4 kBytes) from disk into the disk cache in RAM.
For example, a typical CPU reads a single L2 cache line of 128 bytes from DRAM into the L2 cache, and a single L1 cache line of 64 bytes from the L2 cache into the L1 cache.
Caches with a prefetch input queue
or more general anticipatory paging policy
go further—they not only read the chunk requested, but guess that the next chunk or two will soon be required, and so prefetch that data into the cache ahead of time.
Anticipatory paging is especially helpful
when the backing store has a long latency to read the first chunk and much shorter times to sequentially read the next few chunks, such as disk storage and DRAM.
A few operating systems go further with a loader that always pre-loads the entire executable into RAM.
A few caches go even further, not only pre-loading an entire file, but also starting to load other related files that may soon be requested, such as the page cache associated with a prefetcher or the web cache associated with link prefetching.
Examples of hardware caches[edit]
CPU cache[edit]
Small memories on or close to the CPU can operate faster than the much larger main memory.[5] Most CPUs since the 1980s have used one or more caches, sometimes in cascaded levels; modern high-end embedded, desktop and server microprocessors may have as many as six types of cache (between levels and functions).[6] Examples of caches with a specific function are the D-cache and I-cache and the translation lookaside buffer for the MMU.
GPU cache[edit]
Earlier graphics processing units (GPUs) often had limited read-only texture caches, and introduced Morton order swizzled textures to improve 2D cache coherency. Cache misses would drastically affect performance, e.g. if mipmapping was not used. Caching was important to leverage 32-bit (and wider) transfers for texture data that was often as little as 4 bits per pixel, indexed in complex patterns by arbitrary UV coordinates and perspective transformations in inverse texture mapping.
As GPUs advanced (especially with GPGPU compute shaders) they have developed progressively larger and increasingly general caches, including instruction caches for shaders, exhibiting increasingly common functionality with CPU caches. For example, GT200 architecture GPUs did not feature an L2 cache, while the Fermi GPU has 768 KB of last-level cache, the Kepler GPU has 1536 KB of last-level cache, and the Maxwell GPU has 2048 KB of last-level cache. These caches have grown to handle synchronisation primitives between threads and atomic operations, and interface with a CPU-style MMU.
DSPs[edit]
Digital signal processors have similarly generalised over the years. Earlier designs used scratchpad memory fed by DMA, but modern DSPs such as Qualcomm Hexagon often include a very similar set of caches to a CPU (e.g. Modified Harvard architecture with shared L2, split L1 I-cache and D-cache).[7]
Translation lookaside buffer[edit]
A memory management unit (MMU) that fetches page table entries from main memory has a specialized cache, used for recording the results of virtual address to physical address translations. This specialized cache is called a translation lookaside buffer (TLB).[8]
In-network cache[edit]
Information-centric networking[edit]
Information-centric networking (ICN) is an approach to evolve the Internet infrastructure away from a host-centric paradigm, based on perpetual connectivity and the end-to-end principle, to a network architecture in which the focal point is identified information (or content or data). Due to the inherent caching capability of the nodes in an ICN, it can be viewed as a loosely connected network of caches, which has unique requirements of caching policies. However, ubiquitous content caching introduces the challenge to content protection against unauthorized access, which requires extra care and solutions.[9]
Unlike proxy servers, in ICN the cache is a network-level solution. Therefore, it has rapidly changing cache states and higher request arrival rates; moreover, smaller cache sizes further impose a different kind of requirements on the content eviction policies. In particular, eviction policies for ICN should be fast and lightweight. Various cache replication and eviction schemes for different ICN architectures and applications have been proposed.
Policies[edit]
Time aware least recently used (TLRU)[edit]
The Time aware Least Recently Used (TLRU)[10] is a variant of LRU designed for the situation where the stored contents in cache have a valid life time. The algorithm is suitable in network cache applications, such as Information-centric networking (ICN), Content Delivery Networks (CDNs) and distributed networks in general. TLRU introduces a new term: TTU (Time to Use). TTU is a time stamp of a content/page which stipulates the usability time for the content based on the locality of the content and the content publisher announcement. Owing to this locality based time stamp, TTU provides more control to the local administrator to regulate in network storage.
In the TLRU algorithm, when a piece of content arrives, a cache node calculates the local TTU value based on the TTU value assigned by the content publisher. The local TTU value is calculated by using a locally defined function. Once the local TTU value is calculated the replacement of content is performed on a subset of the total content stored in cache node. The TLRU ensures that less popular and small life content should be replaced with the incoming content.
Least frequent recently used (LFRU)[edit]
The Least Frequent Recently Used (LFRU)[11] cache replacement scheme combines the benefits of LFU and LRU schemes. LFRU is suitable for ‘in network’ cache applications, such as Information-centric networking (ICN), Content Delivery Networks (CDNs) and distributed networks in general. In LFRU, the cache is divided into two partitions called privileged and unprivileged partitions. The privileged partition can be defined as a protected partition. If content is highly popular, it is pushed into the privileged partition. Replacement of the privileged partition is done as follows: LFRU evicts content from the unprivileged partition, pushes content from privileged partition to unprivileged partition, and finally inserts new content into the privileged partition. In the above procedure the LRU is used for the privileged partition and an approximated LFU (ALFU) scheme is used for the unprivileged partition, hence the abbreviation LFRU.
The basic idea is to filter out the locally popular contents with ALFU scheme and push the popular contents to one of the privileged partition.
Weather forecast[edit]
Back in 2010 The New York Times suggested «Type ‘weather’ followed by your zip code.»[12] By 2011, the use of smartphones with weather forecasting options was overly taxing AccuWeather servers; two requests within the same park would generate separate requests. An optimization by edge-servers to truncate the GPS coordinates to fewer decimal places meant that the cached results from the earlier query would be used. The number of to-the-server lookups per day dropped by half.[13]
Software caches[edit]
Disk cache[edit]
While CPU caches are generally managed entirely by hardware, a variety of software manages other caches. The page cache in main memory, which is an example of disk cache, is managed by the operating system kernel.
While the disk buffer, which is an integrated part of the hard disk drive or solid state drive, is sometimes misleadingly referred to as «disk cache», its main functions are write sequencing and read prefetching. Repeated cache hits are relatively rare, due to the small size of the buffer in comparison to the drive’s capacity. However, high-end disk controllers often have their own on-board cache of the hard disk drive’s data blocks.
Finally, a fast local hard disk drive can also cache information held on even slower data storage devices, such as remote servers (web cache) or local tape drives or optical jukeboxes; such a scheme is the main concept of hierarchical storage management. Also, fast flash-based solid-state drives (SSDs) can be used as caches for slower rotational-media hard disk drives, working together as hybrid drives or solid-state hybrid drives (SSHDs).
Web cache[edit]
Web browsers and web proxy servers employ web caches to store previous responses from web servers, such as web pages and images. Web caches reduce the amount of information that needs to be transmitted across the network, as information previously stored in the cache can often be re-used. This reduces bandwidth and processing requirements of the web server, and helps to improve responsiveness for users of the web.[14]
Web browsers employ a built-in web cache, but some Internet service providers (ISPs) or organizations also use a caching proxy server, which is a web cache that is shared among all users of that network.
Another form of cache is P2P caching, where the files most sought for by peer-to-peer applications are stored in an ISP cache to accelerate P2P transfers. Similarly, decentralised equivalents exist, which allow communities to perform the same task for P2P traffic, for example, Corelli.[15]
Memoization[edit]
A cache can store data that is computed on demand rather than retrieved from a backing store. Memoization is an optimization technique that stores the results of resource-consuming function calls within a lookup table, allowing subsequent calls to reuse the stored results and avoid repeated computation. It is related to the dynamic programming algorithm design methodology, which can also be thought of as a means of caching.
Content delivery network[edit]
A content delivery network (CDN) is a network of distributed servers that deliver pages and other Web content to a user, based on the geographic locations of the user, the origin of the web page and the content delivery server.
CDNs began in the late 1990s as a way to speed up the delivery of static content, such as HTML pages, images and videos. By replicating content on multiple servers around the world and delivering it to users based on their location, CDNs can significantly improve the speed and availability of a website or application. When a user requests a piece of content, the CDN will check to see if it has a copy of the content in its cache. If it does, the CDN will deliver the content to the user from the cache.[16]
Cloud storage gateway[edit]
A cloud storage gateway, also known as an edge filer, is a hybrid cloud storage device that connects a local network to one or more cloud storage service, typically an object storage service such as Amazon S3. It provides a cache for frequently accessed data, providing high speed local access to frequently accessed data in the cloud storage service. Cloud storage gateways also provide additional benefits such as accessing cloud object storage through traditional file serving protocols as well as continued access to cached data during connectivity outages.[17]
Other caches[edit]
The BIND DNS daemon caches a mapping of domain names to IP addresses, as does a resolver library.
Write-through operation is common when operating over unreliable networks (like an Ethernet LAN), because of the enormous complexity of the coherency protocol required between multiple write-back caches when communication is unreliable. For instance, web page caches and client-side network file system caches (like those in NFS or SMB) are typically read-only or write-through specifically to keep the network protocol simple and reliable.
Search engines also frequently make web pages they have indexed available from their cache. For example, Google provides a «Cached» link next to each search result. This can prove useful when web pages from a web server are temporarily or permanently inaccessible.
Database caching can substantially improve the throughput of database applications, for example in the processing of indexes, data dictionaries, and frequently used subsets of data.
A distributed cache[18] uses networked hosts to provide scalability, reliability and performance to the application.[19] The hosts can be co-located or spread over different geographical regions.
Buffer vs. cache[edit]
The semantics of a «buffer» and a «cache» are not totally different; even so, there are fundamental differences in intent between the process of caching and the process of buffering.
Fundamentally, caching realizes a performance increase for transfers of data that is being repeatedly transferred. While a caching system may realize a performance increase upon the initial (typically write) transfer of a data item, this performance increase is due to buffering occurring within the caching system.
With read caches, a data item must have been fetched from its residing location at least once in order for subsequent reads of the data item to realize a performance increase by virtue of being able to be fetched from the cache’s (faster) intermediate storage rather than the data’s residing location. With write caches, a performance increase of writing a data item may be realized upon the first write of the data item by virtue of the data item immediately being stored in the cache’s intermediate storage, deferring the transfer of the data item to its residing storage at a later stage or else occurring as a background process. Contrary to strict buffering, a caching process must adhere to a (potentially distributed) cache coherency protocol in order to maintain consistency between the cache’s intermediate storage and the location where the data resides. Buffering, on the other hand,
- reduces the number of transfers for otherwise novel data amongst communicating processes, which amortizes overhead involved for several small transfers over fewer, larger transfers,
- provides an intermediary for communicating processes which are incapable of direct transfers amongst each other, or
- ensures a minimum data size or representation required by at least one of the communicating processes involved in a transfer.
With typical caching implementations, a data item that is read or written for the first time is effectively being buffered; and in the case of a write, mostly realizing a performance increase for the application from where the write originated. Additionally, the portion of a caching protocol where individual writes are deferred to a batch of writes is a form of buffering. The portion of a caching protocol where individual reads are deferred to a batch of reads is also a form of buffering, although this form may negatively impact the performance of at least the initial reads (even though it may positively impact the performance of the sum of the individual reads). In practice, caching almost always involves some form of buffering, while strict buffering does not involve caching.
A buffer is a temporary memory location that is traditionally used because CPU instructions cannot directly address data stored in peripheral devices. Thus, addressable memory is used as an intermediate stage. Additionally, such a buffer may be feasible when a large block of data is assembled or disassembled (as required by a storage device), or when data may be delivered in a different order than that in which it is produced. Also, a whole buffer of data is usually transferred sequentially (for example to hard disk), so buffering itself sometimes increases transfer performance or reduces the variation or jitter of the transfer’s latency as opposed to caching where the intent is to reduce the latency. These benefits are present even if the buffered data are written to the buffer once and read from the buffer once.
A cache also increases transfer performance. A part of the increase similarly comes from the possibility that multiple small transfers will combine into one large block. But the main performance-gain occurs because there is a good chance that the same data will be read from cache multiple times, or that written data will soon be read. A cache’s sole purpose is to reduce accesses to the underlying slower storage. Cache is also usually an abstraction layer that is designed to be invisible from the perspective of neighboring layers.
See also[edit]
- Cache coloring
- Cache hierarchy
- Cache-oblivious algorithm
- Cache stampede
- Cache language model
- Cache manifest in HTML5
- Dirty bit
- Five-minute rule
- Materialized view
- Memory hierarchy
- Pipeline burst cache
- Temporary file
References[edit]
- ^
«Cache». Oxford Dictionaries. Oxford Dictionaries. Archived from the original on 18 August 2012. Retrieved 2 August 2016. - ^ Zhong, Liang; Zheng, Xueqian; Liu, Yong; Wang, Mengting; Cao, Yang (February 2020). «Cache hit ratio maximization in device-to-device communications overlaying cellular networks». China Communications. 17 (2): 232–238. doi:10.23919/jcc.2020.02.018. ISSN 1673-5447. S2CID 212649328.
- ^ Bottomley, James (1 January 2004). «Understanding Caching». Linux Journal. Retrieved 1 October 2019.
- ^
John L. Hennessy; David A. Patterson (2011). Computer Architecture: A Quantitative Approach. Elsevier. pp. B–12. ISBN 978-0-12-383872-8. - ^ Su, Chao; Zeng, Qingkai (10 June 2021). Nicopolitidis, Petros (ed.). «Survey of CPU Cache-Based Side-Channel Attacks: Systematic Analysis, Security Models, and Countermeasures». Security and Communication Networks. 2021: 1–15. doi:10.1155/2021/5559552. ISSN 1939-0122.
- ^ «Intel Broadwell Core i7 5775C ‘128MB L4 Cache’ Gaming Behemoth and Skylake Core i7 6700K Flagship Processors Finally Available In Retail». 25 September 2015.Mentions L4 cache. Combined with separate I-Cache and TLB, this brings the total ‘number of caches (levels+functions) to 6
- ^ «qualcom Hexagon DSP SDK overview».
- ^ Frank Uyeda (2009). «Lecture 7: Memory Management» (PDF). CSE 120: Principles of Operating Systems. UC San Diego. Retrieved 4 December 2013.
- ^ Bilal, Muhammad; et al. (2019). «Secure Distribution of Protected Content in Information-Centric Networking». IEEE Systems Journal. 14 (2): 1–12. arXiv:1907.11717. Bibcode:2020ISysJ..14.1921B. doi:10.1109/JSYST.2019.2931813. S2CID 198967720.
- ^ Bilal, Muhammad; et al. (2017). «Time Aware Least Recent Used (TLRU) Cache Management Policy in ICN». IEEE 16th International Conference on Advanced Communication Technology (ICACT): 528–532. arXiv:1801.00390. Bibcode:2018arXiv180100390B. doi:10.1109/ICACT.2014.6779016. ISBN 978-89-968650-3-2. S2CID 830503.
- ^ Bilal, Muhammad; et al. (2017). «A Cache Management Scheme for Efficient Content Eviction and Replication in Cache Networks». IEEE Access. 5: 1692–1701. arXiv:1702.04078. Bibcode:2017arXiv170204078B. doi:10.1109/ACCESS.2017.2669344. S2CID 14517299.
- ^ Simon Mackie (3 May 2010). «9 More Simple Google Search Tricks». New York Times.
- ^ Chris Murphy (30 May 2011). «5 Lines Of Code In The Cloud». InformationWeek. p. 28.
300 million to 500 million fewer requests a day handled by AccuWeather servers
- ^ Multiple (wiki). «Web application caching». Docforge. Archived from the original on 12 December 2019. Retrieved 24 July 2013.
- ^ Gareth Tyson; Andreas Mauthe; Sebastian Kaune; Mu Mu; Thomas Plagemann. Corelli: A Dynamic Replication Service for Supporting Latency-Dependent Content in Community Networks (PDF). MMCN’09. Archived from the original (PDF) on 18 June 2015.
- ^ «Globally Distributed Content Delivery, by J. Dilley, B. Maggs, J. Parikh, H. Prokop, R. Sitaraman and B. Weihl, IEEE Internet Computing, Volume 6, Issue 5, November 2002» (PDF). Archived (PDF) from the original on 9 August 2017. Retrieved 25 October 2019.
- ^ «Definition: cloud storage gateway». SearchStorage. July 2014.
- ^ Paul, S; Z Fei (1 February 2001). «Distributed caching with centralized control». Computer Communications. 24 (2): 256–268. CiteSeerX 10.1.1.38.1094. doi:10.1016/S0140-3664(00)00322-4.
- ^ Khan, Iqbal (July 2009). «Distributed Caching on the Path To Scalability». MSDN. 24 (7).
Further reading[edit]
- «What Every Programmer Should Know About Memory»
- «Caching in the Distributed Environment»
кеш-память
- кеш-память
-
кеш-па/мять, кеш-па/мяти
Слитно. Раздельно. Через дефис..
.
Смотреть что такое «кеш-память» в других словарях:
-
кеш-память — ж.; = кэш память Толковый словарь Ефремовой. Т. Ф. Ефремова. 2000 … Современный толковый словарь русского языка Ефремовой
-
Кеш-память — Кэш (англ. cache[1], произносится kæʃ кЭш) промежуточный буфер с быстрым доступом, содержащий копию той информации, которая хранится в памяти с менее быстрым доступом, но с наибольшей вероятностью может быть оттуда запрошена. Доступ к данным в… … Википедия
-
Память (компьютер) — НЖМД объёмом 45 Мб 1980 х годов выпуска, и 2000 х годов выпуска Модуль оперативной памяти, вставленный в материнскую плату Компьютерная память (устройство хранения информации, запоминающее устройство) часть вычислительной машины, физическое… … Википедия
-
Память (компьютерная) — НЖМД объёмом 45 Мб 1980 х годов выпуска, и 2000 х годов выпуска Модуль оперативной памяти, вставленный в материнскую плату Компьютерная память (устройство хранения информации, запоминающее устройство) часть вычислительной машины, физическое… … Википедия
-
Память (значения) — Содержание 1 В психологии 2 В компьютерной технике … Википедия
-
Быстрая кеш-память — Промежуточное место, где хранятся наиболее востребованные при работе процессора операнды и данные … Глоссарий терминов бытовой и компьютерной техники Samsung
-
Кеш — Кэш (англ. cache[1], произносится kæʃ кЭш) промежуточный буфер с быстрым доступом, содержащий копию той информации, которая хранится в памяти с менее быстрым доступом, но с наибольшей вероятностью может быть оттуда запрошена. Доступ к данным в… … Википедия
-
Память с произвольной выборкой — Варианты конструкции модулей RAM, используемые в качестве ОЗУ компьютеров. Сверху вниз: DIP, SIPP, SIMM 30 pin, SIMM 72 pin, DIMM, DDR DIMM Запоминающее устройство с произвольным доступом ЗУПД (или Запоминающее устройство произвольной выборки… … Википедия
-
Память с произвольным доступом — Варианты конструкции модулей RAM, используемые в качестве ОЗУ компьютеров. Сверху вниз: DIP, SIPP, SIMM 30 pin, SIMM 72 pin, DIMM, DDR DIMM Запоминающее устройство с произвольным доступом ЗУПД (или Запоминающее устройство произвольной выборки… … Википедия
-
Компьютерная память — НЖМД объёмом 44 Мб 1980 х годов выпуска и CompactFlash на 2 Гб 2000 х годов выпуска … Википедия
Когда не работает какой-то сайт или сервис, от техподдержки часто можно услышать «Почистите кэш и перезагрузите страницу». Иногда это помогает. Рассказываем, почему так происходит, что такое кэш, зачем он нужен и как его почистить.
⚠️ Минутка грамотности. По словарю РАН слово cache в русском пишется «кеш». Но по рекомендациям Гиляревского нужно писать «кэш». И нам нравится, как это произносится. Произнесите вместе с нами:
- КЭШ
- КЭ-ЭШ
- КЭ-Э-Э-Ш
Спасибо.
Что такое кэш
Кэш — это данные, которые компьютер уже получил и использовал один раз, а потом сохранил на будущее. Смысл кэша в том, чтобы в следующий раз взять данные не с далёкого и медленного сервера, а из собственного быстрого кэша. То же самое, что закупиться продуктами на неделю и потом ходить не в магазин, а в холодильник.
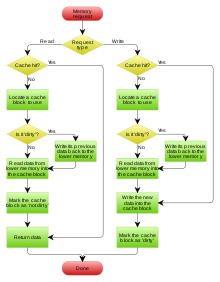
В случае с браузером это работает так:
- Браузер сделал запрос на сервер.
- Сервер в ответ прислал страницу, скрипты и все картинки.
- ❤️ Браузер сохранил всё это в память ← это и есть кэш.

Дальше происходит так:
4. Если вкладкой или браузером долго не пользовались, операционная система выгружает из оперативной памяти все страницы, чтобы освободить место для других программ.
5. Если переключиться назад на браузер, он моментально сходит в кэш, возьмёт оттуда загруженную страницу и покажет её на экране.

Получается, что если браузер будет брать из кэша только постоянные данные и скачивать с сервера только что-то новое, то страница будет загружаться гораздо быстрее. Выходит, главная задача браузера — понять, какой «срок годности» у данных в кэше и через какое время их надо запрашивать заново.
👉 Например, браузер может догадаться, что большая картинка на странице вряд ли будем меняться каждые несколько секунд, поэтому имеет смысл подержать её в кэше и не загружать с сервера при каждом посещении. Поэтому в кэше часто хранятся картинки, видеоролики, звуки и другие декоративные элементы страницы.
👉 Для сравнения: браузер понимает, что ответ сервера на конкретный запрос пользователя кэшировать не надо — ведь ответы могут очень быстро меняться. Поэтому ответы от сервера браузер не кэширует.
Какая проблема с кэшем
На первый взгляд кажется, что кэш — это прекрасно: данные уже загружены, к ним можно быстро обратиться и достать оттуда всё, что нужно, без запроса к серверу на другом конце планеты.
Но представьте такую ситуацию: вы заходите в интернет-магазин обуви, в котором покупали уже много раз, но товары почему-то не добавляются в корзину. Или добавляются, но кнопка «Оплатить» не работает. Чаще всего причина в том, что браузер делает так:
- Вы вводите адрес интернет-магазина.
- Браузер смотрит в кэше, есть ли у него какие-то данные от этого сайта и что у них со сроком годности.
- В прошлый раз сервер не сказал браузеру, что у скриптов со сроком годности, поэтому браузер считает все скрипты свежими. А на самом деле для корзины сервер уже использует новый скрипт.
- Браузер берёт старый скрипт из кэша, подгружает с сайта фотки новых товаров и собирает страницу со старым скриптом.
- Вы нажимаете на кнопку, запускается старый скрипт.
- Сервер не отвечает, потому что рассчитывает уже на новый скрипт.
- Через 3 минуты терпение лопается, и вы уходите на Алиэкспресс за комплектом для кастомной клавиатуры.

Решение — почистить кэш
Когда мы чистим кэш, оттуда удаляются все данные, которые браузер сохранил «на всякий случай». Это значит, что при обновлении страницы браузер заглянет в кэш, увидит, что там пусто и запросит все данные с сервера заново. Они, конечно, тоже сразу отправятся в кэш, но в следующий раз вы уже будете знать, что делать.
Чтобы очистить кэш в Сафари, достаточно нажать ⌥+⌘+E, а в Хроме — нажать Ctrl+Shift+Backspace (⇧+⌘+Backspace) и выбрать время, в пределах которого нужно очистить кэш:
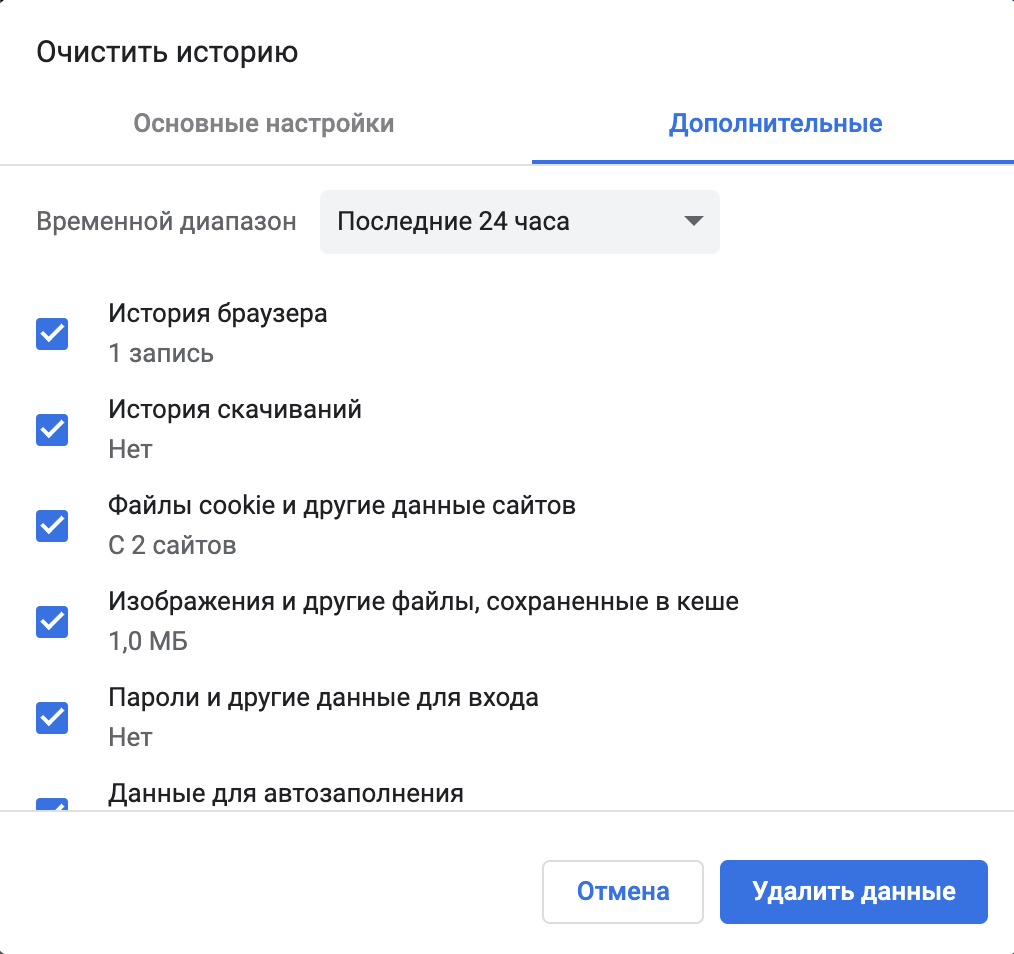
Зачем нужен кэш, если из-за него всё ломается?
На самом деле всё ломается не из-за кэша, а из-за неправильных настроек сервера, которые отдают страницу. Потому что именно сервер должен сказать браузеру: «Вот это можно кэшировать, а вон то лучше не кэшируй, мало ли что».
Часто разработчики недокручивают эти настройки, и браузер не получает нужных инструкций, поэтому кэширует всё подряд. И тогда приходится вмешиваться, чистить кэш и восстанавливать работоспособность.
Не надо так.
Вёрстка:
Кирилл Климентьев
- cache |kæʃ| — кэш, тайник, тайный склад, запас провианта, сверхоперативная память
кэш-блок — cache block
кэш-буфер — cache buffer
кэш данных — data cache
кэш команд — instruction cache
кэш-сервер — cache server
кэш файлов — file cache
внешний кэш — external cache memory
кэш клиента — client cache
входной кэш — ingress cache
кэш свойств — property cache
экранный кэш — screen cache
стековый кэш — stack cache
кэш загрузки — download cache
выходной кэш — egress cache
сдвоенный кэш — dual cache
внесхемный кэш — off-chip cache
страничный кэш — page cache
внутренний кэш — inernal cache memory
шина кэш-памяти — cache bus
блок кэш-памяти — cache unit
кэш-буфер диска — disc cache
тактируемый кэш — clock-forwarded cache
виртуальный кэш — virtual cache
кэш-буфер шрифта — font cache
библиотечный кэш — library cache
внутрисхемный кэш — on-chip cache
многопортовый кэш — multiport cache
кэш второго уровня — level-two cache
кэш вывода страниц — page output cache
несимметричный кэш — skewed cache
ещё 27 примеров свернуть
Смотрите также
кэш/прокси-сервер — cache/proxy server
факультативная кэш-память — optional cash memory
режим блокировки записи в кэш — noncacheable mode
система кэш-буферов, система кэшей — multiple caches
буферный каталог (помещенный в кэш) — cached catalog
дисковая матрица со встроенной кэш-памятью — integrated cashed disk array
режим хранения данных в кэш-памяти с защитой от записи — cacheable-write-protect mode
накладные расходы в случае отсутствия нужных данных в кэш-памяти — miss penalty
режим с блокировкой записи в кэш и с непоследовательной передачей — noncacheable nonserialized mode
режим с занесением данных в кэш-память; режим, допускающий кэширование — cacheable mode
область адресного пространства памяти с запрещением отображения в кэш-памяти — noncacheable region of memory
накладные расходы на изменение содержимого кэш-памяти в случае отсутствия в ней необходимых данных — cache-miss penalty
Родственные слова, либо редко употребляемые в данном значении
- caching |ˈkæʃɪŋ| —
организация обмена с дисковой памятью через кэш; оптимизирующий ввод — disk caching
1Сергей
27.04.16 — 08:19
Всего мнений: 20
Как рассово верно перевести на русский вражеское слово «cache»?
1Сергей
1 — 27.04.16 — 08:20
переименуйте, плиз — «кэш» или «кеш»
Маратыч
2 — 27.04.16 — 08:21
(1) Бгеге.
(0) Транскрипция же. в этом слове «a» звучит ближе к русскому «э», как читаем, так и пишем.
XLife
3 — 27.04.16 — 08:21
1Сергей
4 — 27.04.16 — 08:21
Гугель настаивает на этом варианте:
Jonny_Khomich
5 — 27.04.16 — 08:22
Рэйв
6 — 27.04.16 — 08:25
(0) в cash «а» — открытый звук.
А "е" - закрытый. Это по сути "йэ"
Так что "КЭШ"
Масянька
7 — 27.04.16 — 08:27
Правильно — «промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удаленного источника, однако её объём существенно ограничен по сравнению с хранилищем исходных данных.»
:)))))))
Jokero
8 — 27.04.16 — 08:27
Народ, среда же только еще
Рэйв
9 — 27.04.16 — 08:28
(7)Представь на мисте были бы темы «Как почистить…» и дальше по тексту:-)
Масянька
10 — 27.04.16 — 08:29
(9) Ага… В заголовке темы :)))))
los_hooliganos
11 — 27.04.16 — 08:30
Правильный перевод — наличные.
1Сергей
12 — 27.04.16 — 08:30
ПромежуточныйБуферСБыстрымДоступомСодержащийИнформациюКотораяМожетБытьЗапрошенаСНаибольшейВероятностьюДоступКДаннымВКэшеОсуществляетсяБыстрееЧемВыборкаИсходныхДанныхИзБолееМедленнойПамятиИлиУдаленногоИсточникаОднакоЕёОбъёмСущественноОграниченПоСравнениюСХранилищемИсходныхДанных = Новый Массив();
Маратыч
13 — 27.04.16 — 08:30
+(11) Или «бабло», действительно.
GROOVY
14 — 27.04.16 — 08:31
1Сергей
15 — 27.04.16 — 08:31
(11) cash и cache — вещи разные
los_hooliganos
16 — 27.04.16 — 08:33
(14) Это значит место, где спрятано украденное бабло, закопанное под деревом, которое знает только держатель главной табуретки.
Рэйв
17 — 27.04.16 — 08:33
(15)Все равно читается «Э»
GROOVY
18 — 27.04.16 — 08:34
(16) Тихо!
Масянька
19 — 27.04.16 — 08:34
(16) У кого карта?
los_hooliganos
20 — 27.04.16 — 08:34
(15) Транскрипция одинаковая.
cincout
21 — 27.04.16 — 08:34
«кэш» звучит лучше чем «кэш», имхо
Рэйв
22 — 27.04.16 — 08:35
(19)У Билли Бонса конечно!:-)
1Сергей
23 — 27.04.16 — 08:35
(22) а она дебетовая или кредитная?
Масянька
24 — 27.04.16 — 08:36
(23) Платиновая, без лимита
MUXACb
25 — 27.04.16 — 08:37
(7) Не совсем правильно. Надо так:
Правильно — «промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в промежуточном буфере с быстрым доступом, содержащем информацию, которая может быть запрошена с наибольшей вероятностью, осуществляется быстрее, чем выборка исходных данных из более медленной памяти или удаленного источника, однако её объём существенно ограничен по сравнению с хранилищем исходных данных.»
Рэйв
26 — 27.04.16 — 08:37
(23)Она ЧЕРНАЯ!
OldMonk
27 — 27.04.16 — 08:48
Тихий омут
28 — 27.04.16 — 08:50
СОЗУ. А то ить набрались словечек буржуйских…
1Сергей
29 — 27.04.16 — 09:05
(28) СОЗУ — это, вроде, железка. Не?
mikecool
30 — 27.04.16 — 09:20
правильно — кешью
Dmitrii
31 — 27.04.16 — 09:25
Мнения разошлись.
Эти считают, что «кэш»:
Кэш// Большой орфографический словарь русского языка / под ред. С. Г. Бархударова, И. Ф. Протченко и Л. И. Скворцова. — 3-е изд. — М.: ОНИКС Мир и Образование, 2007. — С. 399. — ISBN 978-5-488-00924-0. — ISBN 978-5-94666-375-5. Большой толковый словарь русского языка / Автор, сост. и гл. ред. С. А. Кузнецов. Институт лингвистических исследований РАН, 2000 Захаренко Е. Н., Комарова Л. Н., Нечаева И. В. Новый словарь иностранных слов. М.: 2003 Толковый словарь по вычислительной технике. Microsoft Press, из-во «Русская Редакция», 1995
solarcold
32 — 27.04.16 — 09:25
Кэш, конечно. Вот если бы оригинальное слово было «kesh» — тогда кеш. А «cash» — это определенно [э], и в английском, и в американском английском, да и в любом другом.
Dmitrii
33 — 27.04.16 — 09:25
А эти полагают, что «кеш»:
Русский орфографический словарь: около 180 000 слов [Электронная версия] / О. Е. Иванова, В. В. Лопатин (отв. ред.), И. В. Нечаева, Л. К. Чельцова. — 2-е изд., испр. и доп. — М.: Российская академия наук. Институт русского языка имени В. В. Виноградова, 2004. — 960 с. — ISBN 5-88744-052-X.
Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0.
Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп,) экз. — ISBN 5-200-01169-3.
1Сергей
34 — 27.04.16 — 09:27
Мне, просто в 1С проще писать Кеш, не знаю почему. Видимо, мой слепой набор плохо помнит букву Э
Azverin
35 — 27.04.16 — 09:30
я помню боролся с «эС 1», а вы тут про «кеш» или «кэш»
aleks_default
36 — 27.04.16 — 09:31
КЫШЬ все работать, рабочий день уже полчаса как начался…
hhhh
37 — 27.04.16 — 09:32
(2) а как правильнее «кафе» или «кафэ» ?
Маратыч
38 — 27.04.16 — 09:32
(36) Маасквичи…
HxC 2-Step
39 — 27.04.16 — 09:33
Вот у 1Сников проблемы то
Маратыч
40 — 27.04.16 — 09:33
(37) Каф’э.
hhhh
41 — 27.04.16 — 09:35
(40) у нас над заправкой висит надпись «КАФЭ». Я всё смеялся, а ведь оказывается, всё правильно написали.
1Сергей
42 — 27.04.16 — 09:35
Сижу я в кине на первом ряде в новом пальте с конфетой во рте
Маратыч
43 — 27.04.16 — 09:39
(40) Я же транскрипцию привел, а не написание Пишется-то «кафе», хехе.
Волшебник
Модератор
44 — 27.04.16 — 09:41
(0) пишется «расово»
Fish
45 — 27.04.16 — 09:41
Навеяло соседней веткой. А как правильно читать QIP? КИП или КВИП?
1Сергей
46 — 27.04.16 — 09:41
(45) Куип
ДенисЧ
47 — 27.04.16 — 09:42
(45) кью-ай-пи
Маратыч
48 — 27.04.16 — 09:42
(46) Ильхам настаивал на «кип» почему-то.
Dotoshin
49 — 27.04.16 — 09:42
cache: варианты перевода имя существительное
кэш
cache тайник cache, stash, drop, crypt, hide, recess
тайный склад cache
сверхоперативная память cache
запас провианта cache
запас зерна или меда cache
тайный склад оружия cache
aleks_default
50 — 27.04.16 — 09:43
(43)Вроде по новым правилам русского языка как слышится — так и пишется, не?
Маратыч
51 — 27.04.16 — 09:43
(50) Я этим новым правилам вращенье придавал на детородном органе. Там и «парашют» через «у» пишется.
Fish
52 — 27.04.16 — 09:43
(50) По каким таким новым правилам?
1Сергей
53 — 27.04.16 — 09:45
(50) мне вот слышится «снек», однако ж правильно «снег»
Fish
54 — 27.04.16 — 09:46
(53) «Закрой за мной дверь, я мухожук»
aleks_default
55 — 27.04.16 — 09:46
(52) Ну госдура недавно что-то такое принимала, я слышал…
Fish
56 — 27.04.16 — 09:46
(55) А можно пруф, что она их приняла?
1Сергей
57 — 27.04.16 — 09:47
пелядь! и эта ветка в политику скатится?
aleks_default
58 — 27.04.16 — 09:47
(56) нельзя
vi0
59 — 27.04.16 — 09:50
(4) странно, а гугл-хром в строке состояния пишет
Состояние кеша
1Сергей
60 — 27.04.16 — 09:51
(59) это у тебя какой-то очень древний хром. В моём нет строки состояния
![]()
vi0
61 — 27.04.16 — 09:52
(60) так это у тебя древний
solarcold
62 — 27.04.16 — 09:52
Кстати, тоже интересно. Давно уже говорили о новых правилах, а приняли ли их на самом деле — непонятно.
Волшебник
Модератор
63 — 27.04.16 — 09:53
(62) Не приняли
Волшебник
Модератор
64 — 27.04.16 — 09:56
Заимствованные слова должны пройти стадию адаптации (десяток-другой лет), когда устаканивается написание и произношение. Слово «кэш/кеш» находится именно в такой стадии. Так что пишите и произносите, как хотите. Победит большинство.
Бубка Гоп
65 — 27.04.16 — 10:37
Произносить проще «кэш», печатать проще «кеш». Но вообще с точки зрения произношения на языке заимствования я за вариант
Изучаю1С8
66 — 27.04.16 — 10:51
Мой брат Кеша говорил что правильно Кэш.
MetaDon
67 — 27.04.16 — 10:54
DomovoiVShoke
68 — 27.04.16 — 10:57
(0)Хз есть ли правило на это дело, но в основном иностранные слова обмягчают и вписывают «е», а произносят «э».
Примеры:
«компьютер», «интернет».
Злопчинский
69 — 27.04.16 — 10:58
Я говорю кэш А пишу кеш Потомучто солнце и лестница
Злопчинский
70 — 27.04.16 — 10:59
DomovoiVShoke
71 — 27.04.16 — 11:06
+(68)Почитал тему, тут некоторые голосуют за произношение. Произношение вроде очевидно что «кэш», думается вопрос в написании.
За что голосуем?
1Сергей
72 — 27.04.16 — 11:28
(71) всей мистой придумываем название переменной
Enterprise
73 — 27.04.16 — 11:32
Карупян
74 — 27.04.16 — 11:36
К старости из твоего лексикона исчезнет буква «Э».
И ты будешь говорить пепси, секс (с) Анекдот
Maniac
75 — 27.04.16 — 11:37
Кишь мишь
marvak
76 — 27.04.16 — 11:47
(0)
Оба варианта употребляются «де-факто» на практике с одинаковой частотой, значит оба допустимы.
По звучанию ближе к оригиналу «Кэш».
marvak
77 — 27.04.16 — 11:51
Оказывается одно из значений cache это "свинцовый контейнер для хранения радиоактивных веществ" )))
Вон оно что!
Часто чистить кэш вредно!
Злопчинский
78 — 27.04.16 — 12:50
(76) из-за таких пофиг стов асе и случается…;-)
© 2022 MakeWord.ru — игра слова из слов, значения слов, синонимы и антонимы. Время загрузки данной страницы 0.0228 сек.
")
Что такое кэш
Кэш (cache) – это совокупность временных копий файлов программ, а также специально отведенное место их хранения для оперативного доступа. Соответственно, кэшированием называется процесс записи этих данных при работе операционной системы и отдельных программ. ОС и приложения кэшируют свои файлы в автоматическом режиме, чтобы впоследствии быстро загружать их из кэша и тем самым быстрее работать.
В чем заключается принцип работы кэша
Большая часть ПО сохраняет свои рабочие файлы в архиве или загружает их на сетевой сервер. Когда пользователь работает с программой, ему требуется некоторое время, чтобы извлечь эти данные. Ускорить процесс можно, сохраняя временные рабочие файлы в кэш, тем самым обходя процедуру разархивации или скачивания. Впоследствии, при очередном обращении программы к этим данным они будут загружаться оперативнее. Чаще всего временные файлы сохраняются в оперативной памяти. Это обусловлено присущей ей высокой скоростью считывания и записи, благодаря чему информация из нее извлекается очень быстро.
Какие существуют способы кэширования
- Аппаратный. В этом случае временные файлы записываются на само устройство в специально отведенные для этого участки памяти. Например, аппаратное кэширование в центральном процессоре выполняется в трех видах cache-памяти – L1, L2 и L3. Это позволяет программам быстро извлечь их при необходимости без обращения к иным устройствам в системе.
- Программный. Кэширование этого типа осуществляется в выделенный участок памяти в операционной системе (как правило, он имеет вид обычной папки). Расположение кэша у различных программ может быть разным. Например, браузеры сохраняют свои временные файлы в свои папки в разделе Document and Settings.
Независимо от того, какой из способов кэширования применяется, этот процесс обеспечивает:
- быстрый доступ к рабочим файлам;
- ускоренную загрузку ПО;
- экономию трафика;
- эффективное использование системных ресурсов;
- повышенную производительность аппаратного и программного обеспечения.
Что такое кэш-память
Кэш-память представляет собой интегрированный в устройство выделенный раздел памяти для сохранения в нем временных рабочих данных и быстрого их извлечения. Она имеется в процессорах и иных устройствах (оперативной памяти, жестком диске) и обеспечивает существенный рост производительности и скорости обработки информации за счет оперативного доступа к нужным файлам. На флеш-накопителях (SSD) ее размер составляет до 4 Гб, на хард-дисках (HHD) – до 256 Мб.

При аппаратном кэшировании временные файлы удаляются, как правило, автоматически, участия пользователя в этом процессе не требуется. Часто он даже не знает о существовании такой системной функции.
Как происходит очистка кэша
Удаление временных рабочих файлов в ОС выполняется, за редким исключением, автоматически и не нуждается в контроле пользователя. Например, для очистки кэша браузера достаточно одновременно нажать комбинацию клавиш Ctrl + F5 на открытой интернет-странице.

В других программах удаление временных данных осуществляется в настройках. Для этого необходимо зайти в соответствующий раздел меню и очистить кэш вручную. В операционной системе Windows таким образом выполняется очистка, как правило, только у браузеров. В iOS на iPhone или iPad данный процесс выполняется в полностью автоматическом режиме, а вот пользователям устройств с ОС Android часто нужно осуществлять его вручную. Однако с выходом каждой новой версии этой операционной системы процедура очистки временных файлов становится более понятной и автоматизированной.
Нужно ли чистить кэш
Иногда кэширование файлов работает некорректно. Из-за этого, например, может загружаться старый контент вместо нового. Зачастую такое случается именно в браузерах. По этой причине кэш необходимо периодически подчищать. Если этого не сделать, то при обновлении данных на сайте (например, при загрузке новых фотографий или изменении стилей) браузер может закачать устаревшую версию контента.

Для его очистки и загрузки актуального содержимого достаточно применить на активной интернет-странице комбинацию Ctrl + F5, после чего она перезагрузится с обновленным наполнением.
В заключение
Мы рассмотрели основные аспекты работы кэша, описали простыми словами, что значит определение, разобрались в назначении процесса и оценили важность регулярной очистки. Эта информация поможет вам эффективно расходовать системные ресурсы своего компьютера, предотвратить возможные сбои при наполнении контентом сайтов, ускорить загрузку и функционирование программного обеспечения. Усвоив эти несложные рекомендации, вы сможете быстрее работать и просто наслаждаться легким и удобным серфингом в интернете.
Другие термины на букву «К»
Все термины SEO-Википедии
Теги термина